Newsgroups最早由Lang于1995收集并在[Lang 1995]中使用。它含有20000篇左右的Usenet文档,几乎平均分配20个不同的新闻组。除了其中4.5%的文档属于两个或两个以上的新闻组以外,其余文档仅属于一个新闻组,因此它通常被作为单标注分类问题来处理。Newsgroups已经成为文本分及聚类中常用的文档集。美国MIT大学Jason Rennie对Newsgroups作了必要的处理,使得每个文档只属于一个新闻组,形成Newsgroups-18828。
STEP ONE:英文词法分析,去除数字、连字符、标点符号、特殊字符,所有大写字母转换成小写,可以用正则表达式
String res[] = line.split("[^a-zA-Z]");
STEP TWO:去停用词,过滤对分类无价值的词
STEP THRE: 词根还原stemming,基于Porter算法
文档预处理类DataPreProcess.java如下
2、特征词的选取
首先统计经过预处理后在所有文档中出现不重复的单词一共有87554个,对这些词进行统计发现:
出现次数大于等于1次的词有87554个
出现次数大于等于3次的词有36456个
出现次数大于等于4次的词有30095个
特征词的选取策略:
策略一:保留所有词作为特征词 共计87554个
策略二:选取出现次数大于等于4次的词作为特征词共计30095个
特征词的选取策略:采用策略一,后面将对两种特征词选取策略的计算时间和平均准确率做对比
测试集与训练集的创建类CreateTrainAndTestSample.java如下
3、贝叶斯算法描述及实现
根据朴素贝叶斯公式,每个测试样例属于某个类别的概率 = 所有测试样例包含特征词类条件概率P(tk|c)之积 * 先验概率P(c)
在具体计算类条件概率和先验概率时,朴素贝叶斯分类器有两种模型
(1) 多项式模型( multinomial model ) –以单词为粒度
类条件概率P(tk|c)=(类c下单词tk在各个文档中出现过的次数之和+1)/(类c下单词总数+训练样本中不重复特征词总数)
先验概率P(c)=类c下的单词总数/整个训练样本的单词总数
伯努利模型(Bernoulli model) –以文件为粒度
(2) 类条件概率P(tk|c)=(类c下包含单词tk的文件数+1)/(类c下单词总数+2)
先验概率P(c)=类c下文件总数/整个训练样本的文件总数
本分类器选用多项式模型计算,根据《Introduction to Information Retrieval 》,多项式模型计算准确率更高
贝叶斯算法的实现有以下注意点:
(1) 计算概率用到了BigDecimal类实现任意精度计算
(2) 用交叉验证法做十次分类实验,对准确率取平均值
(3) 根据正确类目文件和分类结果文计算混淆矩阵并且输出
(4) Map<String,Double> cateWordsProb key为“类目_单词”, value为该类目下该单词的出现次数,避免重复计算
贝叶斯算法实现类如下 NaiveBayesianClassifier.java
4 朴素贝叶斯算法对newsgroup文档集做分类的结果
为方便计算混淆矩阵,将类目编号如下
0 alt.atheism
1 comp.graphics
2 comp.os.ms-windows.misc
3comp.sys.ibm.pc.hdwar
4comp.sys.mac.hardwar
5 comp.windows.x
6 misc.forsale
7 rec.autos
8 rec.motorcycles
9 rec.sport.baseball
10 rec.sport.hockey
11 sci.crypt
12 sci.electronics
13 sci.med
14 sci.space
15 soc.religion.christian
16 talk.politics.guns
17 talk.politics.mideast
18 talk.politics.misc
19 talk.religion.misc
贝叶斯算法分类结果-混淆矩阵表示,以交叉验证的第6次实验结果为例,分类准确率达到80.47%
程序运行硬件环境:Intel Core 2 Duo CPU T5750 2GHZ, 2G内存,实验结果如下
取所有词共87554个作为特征词:10次交叉验证实验平均准确率78.19%,用时23min,准确率范围75.65%-80.47%,第6次实验准确率超过80%
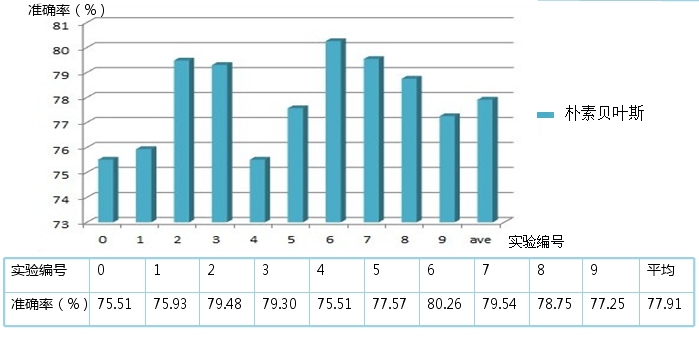
取出现次数大于等于4次的词共计30095个作为特征词: 10次交叉验证实验平均准确率77.91%,用时22min,准确率范围75.51%-80.26%,第6次实验准确率超过80%
结论:朴素贝叶斯算法不必去除出现次数很低的词,因为出现次数很低的词的IDF比较 大,去除后分类准确率下降,而计算时间并没有显著减少
5 贝叶斯算法的改进
为了进一步提高贝叶斯算法的分类准确率,可以考虑
(1) 优化特征词的选取策略
(2)改进多项式模型的类条件概率的计算公式,改进为类条件概率P(tk|c)=(类c下单词tk在各个文档中出现过的次数之和+0.001)/(类c下单词总数+训练样本中不重复特征词总数),分子当tk没有出现时,只加0.001,这样更加精确的描述的词的统计分布规律,做此改进后的混淆矩阵如下
可以看到第6次分组实验的准确率提高到84.79%,第7词分组实验的准确率达到85.24%,平均准确率由77.91%提高到了82.23%,优化效果还是很明显的







相关推荐
。。。
。。。
基于贝叶斯及KNN算法的newsgroup文本分类器,eclipse工程 程序运行方法:用eclipse打开工程,并将newsgroup文档集解压到 F:\DataMiningSample\orginSample目录下,同时在F:\DataMiningSample\ 下建好如附件“F盘...
基于贝叶斯及KNN算法的newsgroup文本分类器,eclipse工程,免积分下载版 程序运行方法:用eclipse打开工程,并将newsgroup文档集解压到 F:\DataMiningSample\orginSample目录下,同时在F:\DataMiningSample\ 下建...
本文为基于贝叶斯算法和KNN算法的文本分类器Java实现,很详细,在网上找的,给大家共享看看
该方法在属性子集搜索上采用遗传算法进行随机搜索,在属性子集评价上采用KNN分类准确率和属性子集规模作为学习算法及评价指标。实验结果表明,该算法可有效地找出具有较好可分离性的属性子集,从而实现降维并提高...
K-近邻算法,又称为 KNN 算法,是数据挖掘技术中原理最简单的算法。 KNN 的工作原理:给定一个已知类别标签的数据训练集,输入没有标签的新数据后,在训练数据集中找到与新数据最临近的 K 个实例。如果这 K 个实例的...
1、资源内容:《机器学习实战》- 约会网站数据的KNN分析-手写数字KNN分析-PLA算法决策树 朴素-贝叶斯-逻辑回归+源代码+文档说明 2、代码特点:内含运行结果,不会运行可私信,参数化编程、参数可方便更改、代码编程...
资源包括代码实现和课程报告--Bayes和KNN分类器实现鸢尾花数据集分类 源码实现包括手撕贝叶斯和KNN以及使用工具包实现 课程报告主要包括以下部分: 一、 问题描述 二、 数据预处理 (1)划分数据集 (2)数据可视化 ...
课程大作业-基于K-means聚类算法和KNN决策判别器的国家经济实力评价matlab源码+数据+报告.zip 第二章 基于K-means的分类统计 5 2.1 K-means介绍 5 2.2 K-means聚类在分类国家经济实力中的应用 7 第三章 基于KNN的...
数据挖掘所需代码,包括KNN算法,贝叶斯,模型评估
1.朴素贝叶斯分类算法 2.KNN分类算法 3.SVM分类算法 4.随机森林分类算法 5.神经网络分类算法 2.数据集 3.KNN图像分类 1.朴素贝叶斯分类算
为了简化系统模型训练方法,提高性别识别系统的整体效率,提出了一种基于改进Citation-KNN算法的说话人性别识别方法。该方法将连续语音切分,训练每段语音的高斯混合模型(Gaussian Mixture Model,GMM)作为多示例...
基于KNN 算法的分类器matlab实现,简单操作,可出图,可根据自身需求修改代码
01.人工智能实验-BP神经网络 02 人工智能实验--kmeans算法对图片的像素点进行聚类 03 人工智能实验--knn算法手写数字的笔迹识别 04 人工智能实验--基于物品的协同过滤...09 人工智能实验--基于贝叶斯算法对情感词分析
Matlab实现基于PSO-NN、SVM、KNN、DT的多特征数据分类预测,二分类及多分类(完整程序和数据) 基于PSO-NN、SVM、KNN、DT的多特征数据分类预测,二分类及多分类(Matlab完整程序和数据) 此代码获取用于分类的数据...
这是一个很简单的KNN算法,每个看看一下都学会,欢迎交流
基于PSO-NN、SVM、KNN、DT的多特征数据分类预测,二分类及多分类(Matlab完整程序和数据) 基于PSO-NN、SVM、KNN、DT的多特征数据分类预测,二分类及多分类(Matlab完整程序和数据) 此代码获取用于分类的数据输入。...
KNN 算法java实现 可以直接用哦
基于MATLAB的KNN算法实现多分类